AI for Games
This article includes my notes and sketch of the class CS-9223 AI FOR GAMES on Spring 2016 taught by Professor Julian Togelius.
This is not a very formal scientific article. It is only supposed to help understand the fundamental concepts about artificial intelligence for games and describe the main ideas about the papers provided by Professor Togelius. I will continuously work on making it much more human readable and accurate.
Update in 2016: check out my co-authored pater! Portfolio Online Evolution in StarCraft
Week 1: Introduction and panoramic overview
A panorama of artificial and computational intelligence in games.
Yannakakis, G. N., & Togelius, J. (2014). A panorama of artificial and computational intelligence in games.
10 AI Study Areas:
- Non-player character (NPC) behavior learning
- Search and planning
- Player modeling
- Games as AI benchmarks
- Procedural content generation
- Computational narrative
- Believable agents
- AI-assisted game design
- General game AI
- AI in commercial games.
3 Views Over Game AI:
- The methods perspective
- The end user perspective
- The player-game interaction perspective
6 Methods:
- evolutionary computation,
- reinforcement learning,
- supervised learning,
- unsupervised learning,
- planning
- tree search
3 dimensions in end user perspective
AI process: what can AI do within games? model, generate and evaluate
Context: what can AI methods model,generate or evaluate in a game? content and behavior
End user:AI can model,generate or evaluate for who? designer, player, AI researcher and producer/publisher
6 AI areas concern the player on a player-game interaction framework
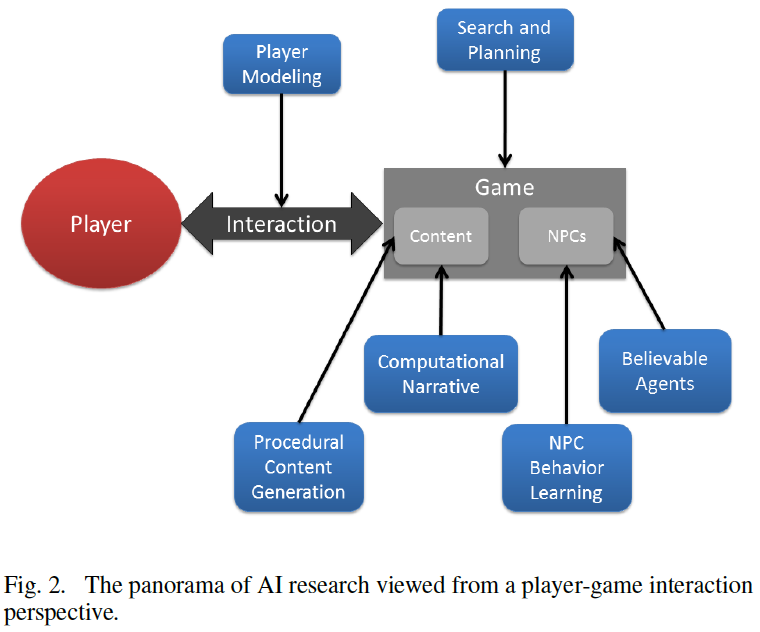
How the research areas influence each other?
See TABLE II in the paper.
AI-Based Game Design Patterns.
Treanor, M., Zook, A., Eladhari, M. P., Togelius, J., Smith, G., Cook, M., … & Smith, A. (2015). AI-Based Game Design Patterns.
Patterns of AI based games:
- AI is visualized
- AI is as a Role-model
- AI as trainee
- AI is editable
- AI is guided
- AI as Co-creator
- AI as Adversary
- AI as Villain
- AI as Spectacle
2 examples:
Contrabot: use AI is visualized, AI as adversary and AI is guided
what are you doing: use AI as trainee , AI is editable and AI is visualized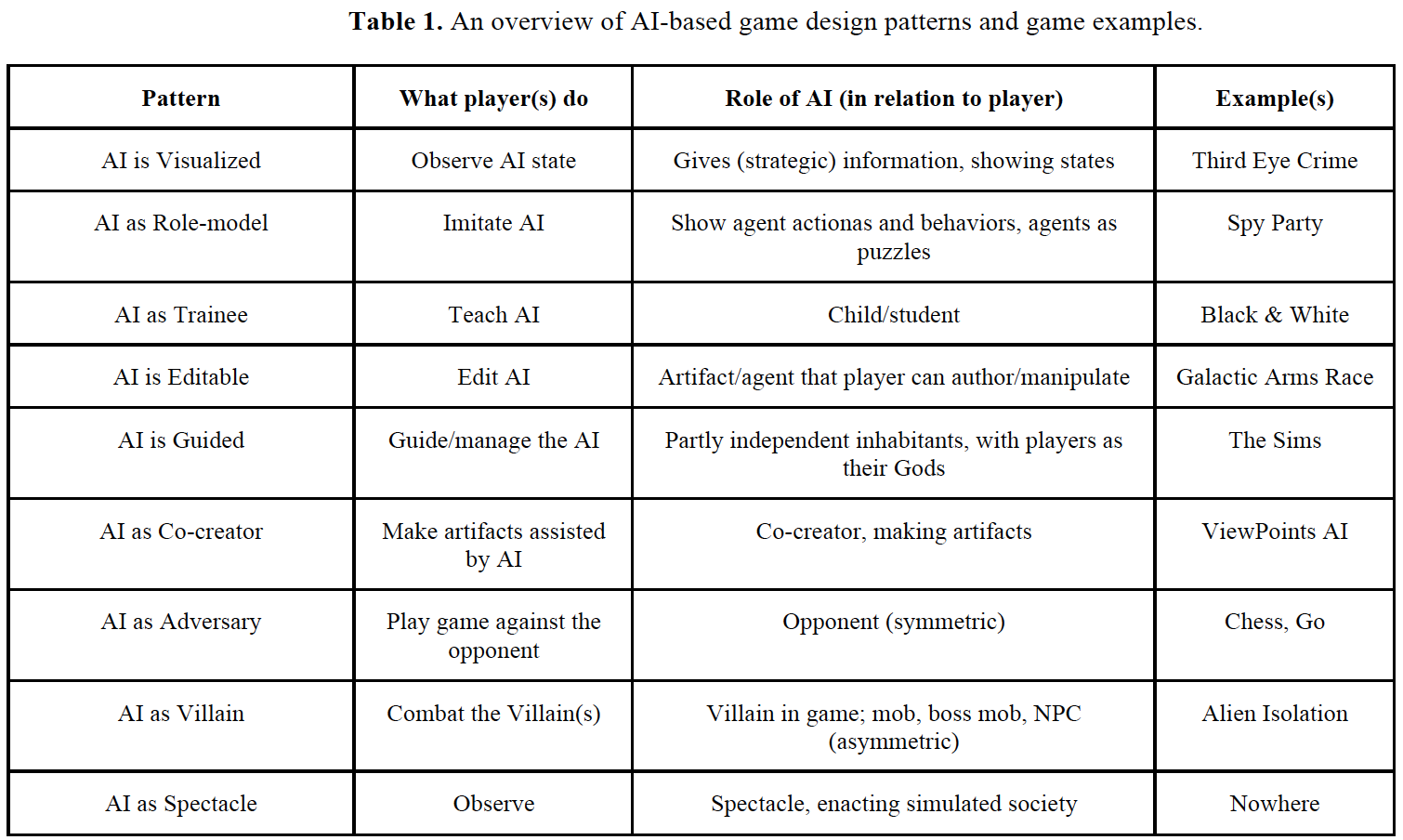
Week 2: Neuroevolution in games
Neuroevolution in Games: State of the Art and Open Challenges
Risi, S., & Togelius, J. (2015). Neuroevolution in Games: State of the Art and Open Challenges. IEEE Transactions on Computational Intelligence and AI in Games.
Section 2: How neuroevolution works (algorithms) and the motivation for using it in games
Neuroevolution Algorithms
Why used in games: record-beating performance; broad application; scalability; diversity; open-ended learning; enables new kinds of games
Why not used in games: its a black box; human don’t know what will happen; hard for quality insurance.
Section 3: The role neuroevolution in games:
State/action evaluation; Direct action selection; selection between strategies; modeling opponent strategy; Content generation; Modeling player experience
Section 4: Newroevolutionary types
- feedforward: the simplest one is a perceptron, no hidden layer, no circle, can only learn to correctly solve linearly separable problems
- recurrent network: with circle and cycles
- modular networks: combine several networks together, each module is responsible for a specific sub-function
- plastic network: the weights can be changed after the training process
- Long-Short Term Memory(LSTM) network : can learn by remembering values for an arbitrary amount of time
Section 5: How networks can be involved
For direct encoding methods: each connection is encoded separately as a real number, employ a one-to-one mapping between the parameter values of the network (e.g. the weights and neurons) and its genetic representation.
Disadvantage: similar solution must be discovered separately
- Conventional neuroevolution (CNE):earliest NE methods, only evolve weight, fixed topology, present the whole network as a vector of real numbers. Drawback: user has to choose the appropriate topology and number of hidden nodes a priori.
- Neuroevolution of Augmenting Topologies (NEAT): evolving the topology together with the connection weights
For indirect encoding methods: reuse info to encode, compact genetic representations
- Compositional Pattern Producing Network (CPPN [115])
- HyperNEAT: is to exploit geometric domain properties to compactly describe the connectivity pattern of a large-scale ANN
- Developmental approaches: the neuron grows (i.e. develops) new synaptic connections while the game is being played
Section 6: How can the neuron network be evolved (fitness function)
- noisy fitness evaluation: (meaning that the same controller can score differently when evaluated several times):evaluating the performance of a controller in multiple independent plays and averaging the resulting scores can be beneficial.
- Incremental evolution: combined with modularisation of neural networks so that each time a new fitness function is added, a new neural network module is added to the mix.
- Example of Incremental evolution:
- transfer learning(accelerate the learning of a target task through knowledge gained during learning of a different but related source task).
- competitive coevolution: the fitness of one AI controlled player depends on its performance when competing against another player drawn from the same population of from another population.
- when deal with multiple fitness criteria:1. cascading elitism, where each generation contains separate selection events for each fitness function, ensuring selection pressure.2. multi-objective evolutionary algorithm (MOEA): try to satisfy all their given objectives (fitness functions)
- interactive evolution: enable new kinds of games, is to allow a human player to interact with evolution by explicitly setting objectives during the evolutionary process, or even to act as a fitness function him or herself
Section 7: Input presentation
- Straight Line Sensors and Pie Slice Sensors
- Angle sensors and relative position sensors
- Pathfinding Sensors
- Third-person Input
- Learning from raw sensory data
Section 8: Open challenges
- Reaching Record-beating Performance
- Comparing and combining evolution with other learning methods
- Learning from high-dimensional/raw data
- General video game playing
- Combining NE with life-long learning
- Competitive and cooperative coevolution
- Fast and reliable methods for commercial games
Real-time Neuroevolution in the NERO Video Game
Stanley, K. O., Bryant, B. D., & Miikkulainen, R. (2005). Real-time neuroevolution in the NERO video game. IEEE Transactions on Evolutionary Computation 9(6), 653-668.
Evolving Robust and Specialized Car Racing Skills
Togelius, J., & Lucas, S. M. (2006). Evolving robust and specialized car racing skills. In IEEE Congress on Evolutionary Computation (pp. 1187-1194). IEEE.
A Neuroevolution Approach to General Atari Game Playing
Hausknecht, M., Lehman, J., Miikkulainen, R., & Stone, P. (2014). A neuroevolution approach to general atari game playing. IEEE Transactions on Computational Intelligence and AI in Games, 6(4), 355-366.
Week 3: Monte Carlo Tree Search, Go and General Video Game Playing
A Survey of Monte Carlo Tree Search Methods
Browne, C. B., Powley, E., Whitehouse, D., Lucas, S. M., Cowling, P., Rohlfshagen, P., … & Colton, S. (2012). A survey of monte carlo tree search methods. IEEE Transactions on Computational Intelligence and AI in Games , 4(1), 1-43.
Monte Mario: Platforming with MCTS
Jacobsen, E. J., Greve, R., & Togelius, J. (2014, July). Monte Mario: platforming with MCTS. In Proceedings of the 2014 conference on Genetic and evolutionary computation (pp. 293-300). ACM.
ABSTRACT
Monte Carlo Tree Search (MCTS) is applied to control the player character in a clone of the popular platform game Super Mario Bros. Standard MCTS is applied through search in state space with the goal of moving the furthest to the right as quickly as possible. Despite parameter tuning, only moderate success is reached. Several modifications to the algorithm are then introduced specifically to deal with the behavioural pathologies that were observed. Two of the modifications are to our best knowledge novel. A combination of these modifications is found to lead to almost perfect play on linear levels. Furthermore, when adding noise to the benchmark, MCTS outperforms the best known algorithm for these levels. The analysis and algorithmic innovations in this paper are likely to be useful when applying MCTS to other video games.
Section 1: INTRODUCTION
- MCTS
Good at playing classic board games such as Go & shown promise when play unseen games (e.g. General Game Playing Competition), not relying on a state evaluation function. However, played in relatively small number of discrete turns, state of the game is discrete and can be described using a relatively small number of variables. I.e. time and state space are highly constrained. - Video games different: continuous-time v.s. continuous-space.
Digital computer: pseudo-continuous.
Open questions: can MCTS used to perform well in pseudo-continuous game domains? How? - Applying MCTS to such domains.
(1) Physical Traveling Salesman Problem (very few actions available per time step and static game world) -> human-competitive performance, but only after several modifications
(2) small-scale combat scenarios - Introduce to Mario AI Benchmark used in this paper.
- Structure of the paper.
Section 2: MONTE CARLO TREE SEARCH
MCTS: evaluation of a node is done by performing random actions from the decision apace until an outcome can be determinated. Anytime algorithm, can be halted. Requires little domain knowledge. (basic implementation only requires knowledge of the action space and a means of simulating the outcome of an action)
- Done by iteratively building a search tree where the nodes are different game states, and the edges are the actions leading to one state from another. A node is added to the tree during each iteration and recursively, based on the reward of the new node, the reward values of parent nodes are updated.
- 4 steps:
(1) Tree policy (A node to be expanded is chosen)
(2) Expansion (The node is expanded by simulating the associated action)
(3) Default polity (The game is simulated following a random path until a terminal node is reached)
(4) Backpropagation (The result propagates up through the tree) - Upper Confidence Bound for Trees(UCT): choose the most urgent node to expand. Benefit: allows for prioritizing between exploitation of seemingly promising nodes(first term) and exploration of less tried nodes(second term).
Section 3: THE MARIO AI BENCHMARK
- Super Mario Bros (SMB).
- Infinite Mario Bros (IMB): Java based clone of SMB.
Section 4: MCTS IN MARIO
- Searching the action space, heaviest computation: simulation of actions on a given state -> impossible to perform the rollout to termination && most result would be death.
- Different evaluation functions for calculating the reward value of a non-terminal state:
(1) x-distance to the right edge of the screen.
(2) Make the value relative to only the position of the parent node and let the maximum reward be the furthest you could potentially go by running directly to the right.
Section 4.1: Parameters
- Roll out cap (Cp). When Cp = 0.25 in the UCB formula, the performance is the best.
- We chose the value of 0.25 for Cp since it has shown good results and behaviour on manual tests
Section 5: MODIFICATIONS TO MCTS
- Not dreadfully bad, but not satisfactory. Far from the elegance of Baumgarten’s A* agent.
- Several failures.
Section 5.1: MinMax rewards
Problem: when calculating the confidence of a node by the average value of its children, single good path among many dangerous ones will only increase the average value slightly.
Solution: exploitation = Q*max + (1-Q)*ave(Xj)
Section 5.2: Macro-actions
Simulating further into the level via a coarse path
Section 5.3: Partial Expansion
- Simulating a move -> time consuming. Half led wrong direction.
- Solution: modify UCB formula. A node is created only under the circumstance that creating it yields a confidence that is larger than all other child nodes.
Section 5.4: Roulette wheel selection
Add a weight to each action
Section 5.5: Domain knowledge
- Removing actions that either don’t add any new options or that we deemed unnecessary -> reduce the set of actions to 10
- Detecting gaps
Section 6: RESULTS
N/A
Section 7: ANALYSIS OF RESULTS
- Most algorithms leads Mario to death
- MCTS is too “random”
Section 8: SECOND TEST: NOISY MARIO
Introduce noise. Each time the action is possibly changed randomly. Under this condition, MCTS performs better than A* algorithm.
Section 9: CONCLUSION
Conclusion for this article
The Grand Challenge of Computer Go: Monte Carlo Tree Search and Extensions
Gelly, S., Kocsis, L., Schoenauer, M., Sebag, M., Silver, D., Szepesvári, C., & Teytaud, O. (2012). The grand challenge of computer Go: Monte Carlo tree search and extensions. Communications of the ACM, 55(3), 106-113.
The 2014 General Video Game Playing Competition
Perez, D., Samothrakis, S., Togelius, J., Schaul, T., Lucas, S., Couëtoux, A., … & Thompson, T. (2015) The 2014 General Video Game Playing Competition. IEEE Transactions on Computational Intelligence and AI in Games.
ABSTRACT
This paper presents: the framework, rules, games, controllers and results of the 1st General Video Game Playing Competition.
Section 1: Introduction
- Game based AI: benchmarking AI algorithms.
- However, almost all existing competitions focus on a single game —–> overfit solution, limiting the value of the benchmark, domain-specific adaptations. AI算法不通用
- This paper: 1st competitions not on a single game.
- 文章结构:相关研究、GVG-AI、比赛规则、controllers、结果
Section 2: Related Research
- Chess作为AI的Benchmark, Deep Blue
- Chess用的Search tree != 其他游戏
- 用比赛作为standard benchmarks
- diversity of competitions. Board games, FPS, car racing, ……
- 不通用,limitations, domain-specific
- General game playing competition. Unseen games
- Another: Arcade Learning Environment (ALE): controller presented with just the raw screen capture and a score controller
- Artificial general intelligence (AGI)
- Game Description Language (GDL)
Section 3: The GVG-AI Framework
VGDL: A Video Game Description Language
A game is defined by 2 separate components:
- Textual level description: 定义起始位置、2D游戏布局
- Game description: 定义和游戏中其他object如何交互。包括:
- LevelMapping: level description —–> object
- SpriteSet: 定义类
- InteractionSet: 定义交互时产生的事件
- TerminationSet: 定义游戏如何结束
The GVG-AI Framework: Java-VGDL
提供interface。必须重写2个方法:constructor和act。这两个方法能够获取系统时间和StateObservation方法。StateObservation表示当前游戏状态并提供forward model,还提供当前时间、分数、状态、可用actions,游戏observations、grid、历史事件等
Section 4: The GVG-AI Competition
- 一大堆游戏规则
- 3组set:training, validation and test
Section 5: Controllers
- A. 1st - adrientx(OLETS)
基于Open Loop Expectimax Tree Search OLETS() - B. 2nd - JinJerry
基于MCTS - C. 6th - culim
Reinforcement learning -> Q-learning - D. 10th - T2Thompson
基于A* - E. Sample controllers
其中一个方法是Sample MCTS - F. Other controllers
Section 6: Conclusions
Conclusions
Week 4: Player modeling
An Inclusive Taxonomy of Player Modeling
Smith, A. M., Lewis, C., Hullett, K., Smith, G., & Sullivan, A. (2011). An inclusive taxonomy of player modeling. University of California, Santa Cruz, Tech. Rep. UCSC-SOE-11-13.
Player Modeling
Yannakakis, G. N., Spronck, P., Loiacono, D., & André, E. (2013). Player Modeling. Artificial and Computational Intelligence in Games, 6, 45-59.
Section 1: Introduction
Definition: The study of computational means for the modeling of player cognitive, behavioral, and affective states which are based on data (or theories) derived from the interaction of a human player with a game.
Goal: The primary goal of player modeling and player experience research is to understand how
the interaction with a game is experienced by individual players.
Core components: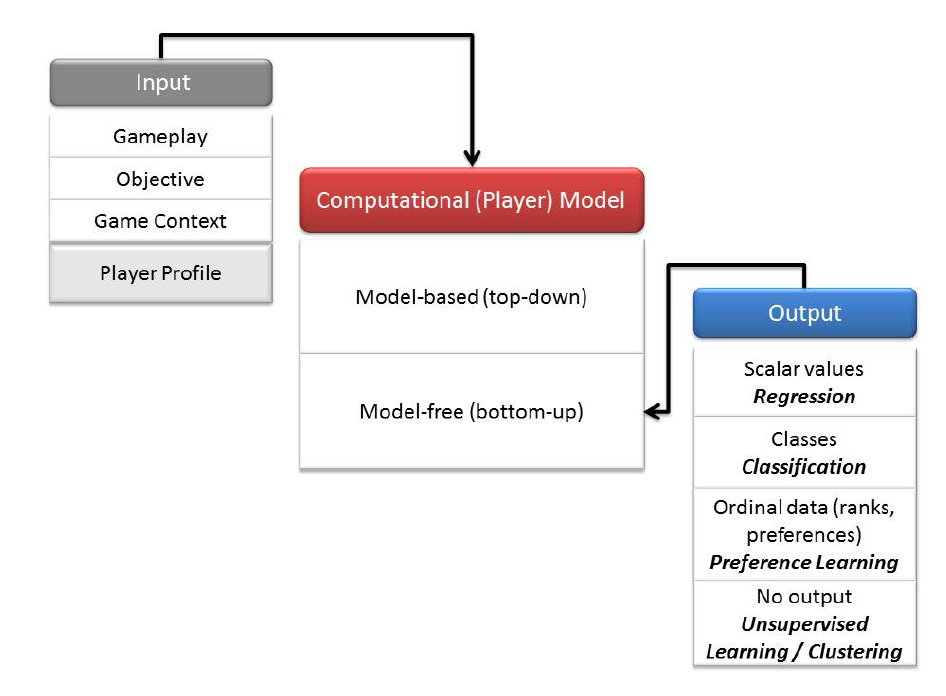
Section 2: Computational Model:
Model-based (top-down) Approaches:
This is built on a theoretical framework. researchers follow the modus operandi of the humanities and social sciences, which hypothesize models to explain phenomena, usually followed by an empirical phase in which they experimentally determine to what extent the hypothesized models fit observations.
Model-free (bottom-up) Approaches:
This refer to the construction of an unknown mapping (model) between (player) input and a player state representation, observations are collected and analyzed to generate models without a strong initial assumption on what the model looks like or even what it captures, Classification, regression and preference learning techniques adopted from machine learning or statistical approaches are commonly used for the construction of a computational model.
Section 3: Input
- Gameplay input: game input
- Objective input: user behavior
- Game context input: what is happening in the game
- Player profile information: static information of the player
Section 4: Output:
A set of particular player states. Such states can be represented as a class, a scalar (or a vector of numbers) that maps to a player state — such as the emotional dimensions of arousal and valence or a behavioral pattern - or a relative strength (preference).
Section 5: Applications:
- Adaptive Player Experience and Game Balancing
- Personalized Game Content Generation
- Towards Believable Agents
- Playtesting Analysis and Game Authoring
- Monetization of free-to-play games
Section 6: Challenges and Questions:
- lack of proper and rich data publicly available to the researchers.
- The use of procedural content generation techniques for the design of better games has reached a peak of interest in commercial and independent game development.
- Nowadays, several modalities or player input are still implausible within commercial game development.
- In the current state of research, model-free approaches seem most suitable
- Player characteristics within a game environment may very well differ from the characteristics of the player when dealing with reality. Thus, validated personality models such as psychology’s Five Factor Model might not fit well to game behavior
- Experience has shown that diligent application of data mining techniques may provide insight into group behaviors. However, it remains difficult to make predictions about individuals.
Introverted Elves & Conscientious Gnomes: the Expression of Personality in World of Warcraft
Yee, N., Ducheneaut, N., Nelson, L., & Likarish, P. (2011, May). Introverted elves & conscientious gnomes: the expression of personality in world of warcraft. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (pp. 753-762). ACM.
ABSTRACT
Personality inference can be used for dynamic personalization of content or system customization. In this study, we examined whether and how personality is expressed in Virtual Worlds (VWs). Survey data from 1,040 World of Warcraft players containing demographic and personality variables was paired with their VW behavioral metrics over a four-month period. Many behavioral cues in VWs were found to be related to personality. For example, Extraverts prefer group activities over solo activities. We also found that these behavioral indicators can be used to infer a player’s personality.
1. Introduction
- Games can be character revealing.
- Virtual worlds: unparalleled platform, (personality != behavior). Online games, inconsistent. Thus we ask 2 questions:
(1) Is it true that a person’s personality can be inferred from how they behave in a virtual world?
(2) If so, what specific virtual cues are highly indicative of a person’s introversion or conscientiousness? - Being able to infer a user’s personality (from online cues) ======> HCI research & help design systems more responsive to users’ needs
- This paper, WoW, to answer the 2 questions, discuss results
2. The Expression of Personality
(1) Judgements of personality at zero acquaintance (i.e. by strangers) are moderately accurate. Personality <—–(express)—– everyday life in specific cues
(2) Personality inference by examining bedroom or office
(3) Computer Mediated Communication(CMC), accurate personality <— Facebook profile, email content, blog content
(4) Personality traces in both physical and digital spaces
3. Limits to personality expression
Reasons that personality not readily expressed in virtual worlds:
(1) Previous study: everyday settings or linguistic output —-> online V.S. non-human bodies doing non-human things in real world
(2) VWs allow reinvent ourselves —> break between (personality) and (behaves in VW)
(3) Users alter behavior in online games
4. The Collection of Personality Data
- Previous: linguistic output or behavioral traces.
- Natural settings (actual behaviors) ——> better understanding of the link between personality and behavior
5. Behavioral Data Collection in Virtual Worlds
- Virtual Worlds: definition
- VWs offers 3 unique features: (1) computer already track the movement and behavior of every avatar (2) high-precision sensors operate at all times (3) observations can be performed unobtrusively
- Previous study: connections between personality and virtual behaviors in VW Second Life.
- 4 Weakness in that study: (1)(2)(3)(4)
6. Research Questions
- Focus on 2 research questions. Whether and how personality is expressed in online games.
(1) What are the behavioral correlates of personality in an online game?
(2) How well can we infer someone’s personality from only observing their virtual behaviors?
7. Method:
- World of Warcraft & Armory
- Participants
8. Procedure
(1) Participants completed web-based survey -> demographic and personality information
(2) Participants list up to 6 WW characters they were actively playing -> automatically collect their characters’ data from WoW Armory
9. Personality Measures
- Big-5 model: Extraversion, Agreeableness, Conscientiousness, Emotional Stability and Openness to Experience
10. Behavioral Measures in WoW
- 2 main complexities:
(1) Armory profiles consist of hundreds of variables & hierarchy —–> to avoid: generating high level variables where possible
(2) Most players have multiple active characters, not clear how to combine. - Normalization:
(1) Static character
(2) Variable character
(3) Metrics that could be normalized against another variable
(4) Metrics that could not be normalized and were highly dependent on character level
(5) Metrics that could not be normalized and were not dependent on character level
11. RESULTS
- Extraversion
- Agreeableness
- Conscientiousness
- Emotional Stability
- Openness to Experience
Evolving Personas for Player Decision Modeling.
Holmgard, C., Liapis, A., Togelius, J., & Yannakakis, G. N. (2014, August). Evolving personas for player decision modeling. In Computational Intelligence and Games (CIG), 2014 IEEE Conference on (pp. 1-8). IEEE.
Week 5: Search-based Procedural Content Generation
Search-based Procedural Content Generation: A Taxonomy and Survey
Togelius, J., Yannakakis, G. N., Stanley, K. O., & Browne, C. (2011). Search-based procedural content generation: A taxonomy and survey.Computational Intelligence and AI in Games, IEEE Transactions on, 3(3), 172-186.
Section 1: Introduction
Search-based procedural content generation是用进化和其他 metaheuristic 算法自动产生游戏内容的方法。通常PCG只用很少的描述 (parameters) 产生具体的内同,通常是部分随机的。PCG 可以省内存,省功夫,产生一直有趣的endless game,产生超出想象力的东西
Section 2: DISSECTING PROCEDURAL CONTENT GENERATION
鉴于相关文档的不全,本节主要讲述一些PCG方法的分类,分类不是binary的而是相互联系。PCG方法不是search base的
A. Online versus offline
online指内容在玩游戏的时候生成,需要有很高的实时性和质量保证。offline指在游戏制作阶段由算法生成并由设计者修缮
B. Necessary versus optional content
前者是玩家必须经历的内容比如地图和怪物,后者是玩家可以选择经历的,比如进入一个房间。区别在于前者必须正确,后者则不然因为玩家可以选择放弃那个content
C.Random seeds versus parameter vectors
都是内容产生需要的输入,差别在于控制的多少。后者比前者约束更多
D. Stochastic versus deterministic generation
完全决定的PCG可以看做一种数据压缩,因为相同的输入一定产生相同的输出,但是大多数PCG是随机的
E. Constructive versus generate-and-test
前者只产生一次内容,然后过程结束,需要保证产生的都是对的内容。可以通过只进行产生不会错内容的操作来达成。后者不但产生还测试,基于一些给定的标准。如果失败了丢弃重做
Section 3: Search Based PCG
这是一种generate-and-test的方法。特点是test的时候不是只接受或者拒绝,而是评估一个值,新产生的内容基于之前得到的评估值以产生更好的value。本文讲的search base大多数都是基于进化算法。第三节所有例子都是用进化算法作为主要搜索机制
A. Content representation and search space
在随机最优和metaheuristic中需要知道如何表示被进化的东西,即基因怎么map到phenotype。表示分为direct encoding和indirect encoding。前者即线性映射,基因的每部分映射到显型的每部分,基因的size多大显型的size就多大,后者则不需要成比例
如何表示已经被研究了一些,其中一个就是candidates作为实数向量,这样易于分析,许多算法也可以使用。向量要有正确的的维度,果断的向量没有表示能力应该避免,向量维度过多也不行。而且表示需要有locality,小的变化只导致小的变化。而且选择的表示要能表示所有有趣的情况,这对indirect encoding来说不容易,direct比较容易
B. Evaluation functions
定这个函数是ill-posed,西药雪顶什么应该最优并且规范化它比如要“fun”这个目标就不好规范化。有三种关键评估函数direct, simulation-based and interactive evaluation functions
direct:一些特征直接从产生的内容提取并映射到fitness value里如房间个数,武器开火率等,这种映射不必是线性的而且不用很多计算,而且可以做到个性定制。直接评估分为theory-driven and data-driven,前者通过感觉或者定性的用户经验理论来映射,后者通过数据收集比如问卷活着物理测量
simulation-based:通过人工agent玩那一部分游戏,充分体验过后评估,比如通过迷宫且不被杀或者和新规则产生的boardgame中的AI敌人对战,然后通过观察来评估。sumulation-based evaluation分为static and dynamic。q前者agent来玩游戏时是不会改变的,后者则会。比如有学习能力的agent。这种评估方法通常计算量更大
Interactive based:通过和玩家交流获得评估分数,在玩游戏过程中评估。可以提问题询问或者看用户如何操作。但这样会打扰用户游戏,除非能很好的集成在游戏内。一些物理检测方法也非常昂贵
C. Situating search-based PCG
search base是generate and test算法,可能以向量作为参数,由于进化需要random seed所以应该算随机方法,你不知道你得到的会是什么结果。你不能保证完成时间和完成质量,所以不适合online 内容产生。
Section 4: Survey of Search Based PCG
本节我们调查发布的论文,我们会尽量cover多的field。以下是survey的顺序:首先examines 必要的游戏内容,然后是optional的,规则和机制,puzzle,track,level,
terrain和map是必要的,weapons,buildings和camera placement 是optional的,我们会按照时间顺序讨论
这后面都是介绍对于这些content已经有的自动产生的例子和别人的使用方法,每个人方法都不同讲的又简略看不懂就不写了
A. necessary content
- 规则和机制:这是游戏最基本的,很少有在游戏时改变的例子
- puzzels: puzzle 通常认为是一类游戏,但是有很多游戏有puzzle的内容,需要在游戏内解决以取得游戏进展,所以是necessary的
- tracks and levels:绝大多数需要控制角色在二维三维空间内行动都是在level内进行,所以角色需要travel,通常伴随完成目标
- terrain and map:这两者概念有些重合,很多游戏都是局域地图和地形简历的,可以看做2D或2.5D平面,一些策略类游戏十分依赖地图,会影响游戏的玩法
- Narrative and story:很多游戏都有剧情或故事,特别是FPS游戏,一些系统能产生美景故事或者可以玩的scenario from scratch,方法主要是constructive和generate- and-test.
核心机制很多是经典的AI planning
B. Optional Content1
- weapons:就是那个太空射击游戏
- buildings:在Subversion游戏中整个城市由玩家逐渐造出,所以单个建筑是optional的,建筑由一种mark-up语言表示,建筑是由进化算法产生不同外观的
- camera control:许多游戏世界内有虚拟相机,控制相机就是控制位置角度等,它是optional因为游戏就算只有差一点的相机也可玩只是更难,但是对于一些对相机要求高的游戏如FPS它就是necessary了
- Trees
Conclusion
绝大多数产生规则和puzzle的例子都用expression tress表示content,而且都用了simulation based evaluation。 level和map最常有direct evaluation
Automatic Content Generation in the Galactic Arms Race Video Game
Hastings, E. J., Guha, R. K., & Stanley, K. O. (2009). Automatic content generation in the galactic arms race video game. IEEE Transactions on Computational Intelligence and AI in Games, 1(4), 245-263.
ABSTRACT
游戏内容要是能够在玩的时候renew会使人更感兴趣,本文介绍两种新技术达成这个目标: 1. Content-generating Neuroevolution of Augmenting Topologies (cgNEAT) 基于玩家表现自动生成游戏内容,2. Galactic Arm Race: 是一个多人游戏,用cgNEAT更新粒子武器系统
Section 1
EC(evolution computing)可以有效帮助内容产生,目标是随着游戏产生新颖的内容局域玩家兴趣
cgNEAT 目标是自动实时产生复杂图形和游戏内容,通过进化算法基于玩家之前喜欢的内容。GAR游戏中,compositional pattern producing networks (CPPNs), which are a variant of artificial neural networks (ANNs),用来编码粒子系统。CPPN通过cgNEAT进化和提升复杂度,通过玩家最常使用的武器。
主要贡献:展示了在多人科幻架构中是如何根据玩家洗好进化内容的,对其他游戏有启发
section2:和本文技术相关的背景材料。section3:cgNEAT的详细描述。section4:cgNEAT是如何在实际中使用进化武器的,section5:单人和多人进化的实验结果section6:总结
Section 2
Interactive Evolutionary Computation (IEC)指人能看到当前一代的content,由人指定谁能繁殖而非fitness foundation,对于fitness function很难以定义的情况很好用。ICE对于进化graph很有效,但是需要有evolvable的结构,本文中的结构是CPPN,一种ANN的特殊情况
CPPN:CPPN和ANN不同之处再去他是模式产生者而不是控制器,ANN通常只包括高斯函数或者s函数,CPPN可以同时使用许多不同的函数,看你需要产生什么模式。比如sin可以产生重复,高斯产生对称。通过选择函数可以产生不同的模式。为了产生完整的图像或模式,cppn通常接受很多输入,因为他是函数的组合
NEAT:普通神经网络evolve ANN是固定或者随机拓扑网络的,,NEAT进化开始于几个小而简单的神经网络,随着代数增加复杂化,使得表现也复杂化。
本文使用NEAT的原因:已经证明可以有效进化CPPN,快到可以实时运行。
Section 3
cgNEAT 方法通过隐性的数据得知用户喜好而不用一直问用户问题,
Algorithm
- 每个content都由一个CPPN表示,不同的content有不同的input/output configuration
- 游戏中每个content都有一个健壮值基于多少人经常使用它,因此系统知道它的受欢迎程度
- 用户开始游戏with随机content或从starter pool里面选,starter pool不参与进化也不能产生后代
- content散布倒游戏世界中,在未被拾取的时候也不参与进化
- content在cgNEAT中按如下方法繁殖:算法选择用户拥有的content繁殖,现则概率基于受欢迎程度,繁殖包括crosscover和mutation通过NEAT算法,因此后代可能更复杂。
- 发布到世界的武器可能来自spawning pool,spawning pool是一些预先进化过的content,不是来自繁殖,这个pool保证多样性不丢失以及从前用户喜欢的形态会再出现。它也确保了一下初始的好content,在游戏刚开始用户洗好还不知道的时候。这个pool在游戏发布前由设计者创造。
- 有很高fitness的content有机会存到content archive。content archive可以作为数据分析的样本,或者放回spawn pool或者把它给NPC对抗玩家
独特特征
cgNeat把NEAT 和进化的一些机制结合。不像EC,本方法的population size不是固定的而是基于玩家数量,而且当后代产生时,并不立刻让后代繁殖,而是放到世界里,除非用户拾取才加入population。不像一般EC使用fitness function,用户通过拾取的丢弃完全决定能否继续繁殖。而且用户并不知道他们在和进化算法交互。
Starter Pool, Spawning Pool and Archive Pool
如果一开始search space里面的武器都很烂,随机分配武器会导致用户的坏印象,所以建立starter pool。因为所有用户都用它开始,所以不参与繁殖和进化。
spawn pool是预先进化好的content库,里面的content都是比较好的。游戏开始时没有用户喜好信息,因此需要这个pool的内容开始进化。这个pool也可以保证用户的好映像。由于NPC使用这个pool的武器,可以保证游戏适宜的难度。archive pool都是fitness很好的content。
GALACTIC ARMS RACE (GAR)
游戏介绍blablabla
游戏中每一个武器都是另一个武器的后代,不会有一个后代的copy出现,武器的强度都是一样的,只是模式不同。武器被拾取前会有预览,CPPN在游戏内是可见的
每个武器都有单独的CPPN,每一帧动画时,每一个粒子的输入是相对于飞船的位置,距离,输出是粒子速度和颜色。
用户射击时改武器以恒定速度获取fitness,武器slot中其他武器同样速率丢失fitness。
用户摧毁飞船时,新武器出现有几种方式:1.从当前population 繁殖而来; 2.从spawning pool; 3随机生成概率为80%,10%,10%
。。一大堆图片和数据
Section 6
对于一些游戏设计者来说,生成新内容可能是危险的因为会lose control,但是实际上
interactive evolutionary dynamic automatically creates a kind of implicit game balance,因为一个用户拿到失衡的武器时,别人也能拿到它的后代,所以一直是平衡的。对于一些线性FPS游戏来说,为了故事的完整性,玩家在某时刻只能拥有某武器是必要的,所以cgNEAT就不适合。
任何想要进化的content必须要有一个参数列表。好的参数应该是可以自由改变,甚至超出社接着的想像。
future work:用户分别拿固定武器和进化武器看谁厉害,或者寻找玩家对于novelty贡献多少,可以通过用户给武器rate,然后比较三种结果1.武器来自正常 进化2.武器随机3.武器来自novelty 搜索。玩家对于美学的要求程度和战术需求要求程度的比较。
Search-based Procedural Generation of Maze-like Levels
Ashlock, D., Lee, C., & McGuinness, C. (2011). Search-based procedural generation of maze-like levels. Computational Intelligence and AI in Games, IEEE Transactions on, 3(3), 260-273.
Abstract
关卡生成是PCG中的关键,本篇讲述自动生成maze map,目的是创造一个进化算法系统给用户一个好的control来生成想要的maze,clus-de-sac, branching和reconvergence以及地图的表示均会提到。
本篇是进化地图所以是search based PCG,不同的表示和fitness function会产生不同外观的maze。本篇的主要贡献是探索encoding maze的不同表示,建立一个框架来设计fitness function,给使用者提供最产生地图特性的客观控制
Section 1: dynamic programming 动态规划
原理是在遍历网络节点的时候记录cost,如果一条新路径的cost小于当前则不变,否则到达一个节点的最小话费更新然后搜索继续。本片中很多地方用到动态规划,每种动态规划算法都有不同fitness function会在第三节阐述。本文结构为:section 2说明几种可进化地图的表示section3: 给出几种敲掉不同地图属性的fitness function 。section4展示实验结果 section5:讨论结果,比较不同 section7 总结
Section 2
“表示”是进化算法的关键,是把主要信息结合的方法,本篇讲述四种表示
- first直接表示:开闭的suqre直接定义为长常的binary gene
- second/chromatic,给格子中的suqres分配颜色,颜色定义为常基因,agent可以在相邻square中移动如果颜色相同或者在{R,O,Y,G,B,V}的颜色alphabet中处于相邻位置
- indirect positive:基因用来定义放置在空grid形式的关卡里的结构,强是explicit,room和corridors是implicit
- indirect negative:染色体定义从填充的grid中移除的material,room和corridors是explicit,walls是implicit
需要考虑的是生成地图是否是可以探索的,在三种表示里可以使用一种叫sparse initialization的技术。它在地图最初放置一些阻碍square,这形成了low fitness的简单maze,但是让所有的初始population都是feasible的,然后增量的产生更复杂和高fitness的maze。
A. details of first direct representation
对于X*Y的地图,crosscover的概p1,mutation概率p2,前者在两个染色体上操作,在每个位置以概率P1交换,后者在一个染色体上以概率p2 flip。进行了两个实验分别是单点和两点crosscover。
B. details of the chromatic representation
对于X*Y的地图,表示是一个由0-5组成的string,0-5分别映射到 {R, O, Y, G, B, V} 六色,两种operation概率为P1和P2(crosscover和mutation)前者以概率P1交换颜色,后者以概率P2改变颜色。
这种方法也需要一种形式的sparse initializatoin。方法是把网格等概率初始化为green和yellow,这样任何两个sucres见都可以通过,而且可以很容易的mutate从而产生barrier
这种表示法的不同在于别的都确定哪个grid是阻塞的,这种并不直接使grid阻塞,而是规定两个squares可以通过的规则,于是有一个隐性的墙。隐性的墙使描绘一个颜色地图耗费的bit要比之前的方法多,因为每一对相邻squares都有潜在的barrier,而不是每一个square是潜在的barrier
C. details of positive,indirect representation
该表示方法储存一个0-9999的整数数组,整数是成对出现,用来在一个只有边缘墙的空地图中表示barrier。第一个整数拆成一个1bit数,一个3bit数和一个其他用来表示barrier的长度。1bit表示barrier是否有穿透性,3bit用来表示barrier的八个方向。第二个整数i分成x=i%X,y=(i/X)%Y作为barrier的起始点。crosscover交换数字,mutation改变数子。有一个额外固定参数LIM,指放下的填充的square最大个数,打到后后面的都skip。这种方法也很可能没有从入口到出口的路径,除非barrier数量少或长度小。所以需要定义barrier的初始长度在1到3之间
D. details of negative, indirect representation
该表示方法储存一个0 - 9999的整数数组,整数是成对出以决定从哪里移除material。从一个初始filled的X * Y的grid里,一对4*4的房间总是放在进出口位置。整数对中第一个整数分成一个2bit数和一个R,2bit数表示类型:skip, north-south corridor, east-west corridor, or room。长度是R modulo X或Y 房间宽 R mod 4+2 高是 (R/4) mod4 +2. 房间和corridor的左上角坐标(A,B)由第二个整数N得到 A = N mod X and B = (N div X) mod Y。这种方法不会产生不能 traversable 的 maze 所以不需要 parse initialization
Section 3: Fitness function
建立fitness function的关键是使用checkpoint,它只是一个位置。标记哪一个checkpoint在进出口的最短路径上可以提供重要的control。在动态规划中,当新的最短路径被发现,任何在该路径上的chckpoiny都被加入checkpoint记录,这样可以产生多条汇聚的路径
。。。。。都是数学公式不看了
有几种fitness:
- exit path length fitness
- primary reconvergence sum fitness 这种要求能达到所有checkpoint
- isolated primary reconvergence sum fitness 它鼓励 path branch, 通过 check point 并且最后会聚
- cul-de-sac count fitness 什么鬼
- cul-de-sac length fitness
Section 4: design of experiment
就是说了一下几个实验的参数是怎么设置的
Section 5: result
F1 只着重与path的长度,所以只产生很少的branch和side corridors,fitness中的参数K用来强制checkpoint在path上,所以可以一定程度上control path的形状
使用F2,所有的坐下checkpint都在long cul-de-sac的末尾,
所有使用F3的checkpoint都在到达exit的不同路径上
Conclusion
第一本文阐述了四种可移动的表达。第二本文定义了一些可以用动态规划计算的elements,用来简历不同fitness function,本文描述了5中fitness function。第三阐述了不同fitness function的不同结果比较。sparse initialization 是一种简单但是有效的方法
Controllable procedural map generation via multiobjective evolution
Togelius, J., Preuss, M., Beume, N., Wessing, S., Hagelbäck, J., Yannakakis, G. N., & Grappiolo, C. (2013). Controllable procedural map generation via multiobjective evolution. Genetic Programming and Evolvable Machines, 14(2), 245-277.
Week 6: Grammar-based and constraint-based PCG
Answer set programming for procedural content generation: A design space approach
Smith, A. M., & Mateas, M. (2011). Answer set programming for procedural content generation: A design space approach. IEEE Transactions on Computational Intelligence and AI in Games, 3(3), 187-200.
Design space: the set of artifacts that will eventually produce given some input
产生过程可能失败由于不希望的artifact 如不可解的谜题出现,甚至使游戏引擎崩溃的内容。为了避免这些需要对design space进行限制。有时候在没产生很多artifact之前你不知道成功或失败,需要有防错机制。artifacts 需要有candidates,candidates的属性有助于修正design space的定义。
ASP有助于改良generative space。我们建议把具体领域的PCG问题作为answer set的规范化问题。因此可以由存在的算法解决。
本文想要在技术,tutorial和survey contribution方面给予同样的重视。我们的技术贡献是吧PCG问题映射到ASP,tutorial贡献是把游戏特点介绍给ASP并且在软件上实验PCG系统的重新实现。我们的survey contribution是回顾两个asp到PCG的应用和两个其他产生非游戏内容的ASP应用
这项工作不仅要产生内容,还要帮助理解什么artifact是需要的
什么鬼都不知道ASP是什么看个毛
On genetic algorithms and Lindenmayer systems
Ochoa, G. (1998). On genetic algorithms and Lindenmayer systems. In Parallel Problem Solving from Nature—PPSN V (pp. 335-344). Springer Berlin Heidelberg.
Abstract
使用L-system绘制植物,用遗传算法改变性状
Niklas的方法:
三个特征用来表示植物分支的模式: 分支概率,分支角度和旋转角度。 植物在几个branch cycle里模拟出来。在进化过程中,在最近的相邻点根据三个分支模式搜索,选择最健壮的称为下一个cycle的起始点,知道搜索空间内的相邻点均不如当前点。
缺点:三个参数太简单,容易在局部最小点卡住,没有考虑到有性生殖。
本文使用L-system 和进化算法。植物基因型由L system表示。该系统有两种进化,交互选择(允许人直接使进化往想要的方向发展)和自动进化(使用进化算法和fitness function)。Section 1: formalism of L-system和图形学解释; Section 2: L-system如何用作进化encoding,该进化算法的特性,基因的操作和fitness function; Section 3: 模拟的结果; section4: 总结
Section 1
L-system 的中心思想是重写,把复杂的对象用简单对象表示,遵循重写规则,重写可以递归。L-system中是同步替换的
DOL-system :a->ab,b->a
turtle: F 向前移动划线, f向前移动不划线, + - 左右转 【】push pop
Section 2
由于树的基因是有语法结构的,所以对基因的操作应该注意不能破坏语法结构。主要操作有crossover和两种mutation
- symbol mutation:{F+-}从基因中选一个符号替换成正确的语法结构
- block mutation: 从基因中选一个block替换成正确的语法结构
进化算法:rather than fixed length string encoding,我们的基因长度可变,每一代1/5 适应度最低的基因被替换
fitness function:直接由基因型判断形状好坏是很难得,所以需要借助人的感知。适应性基于以下特征:1.趋光性2.双边平衡性3.采光能力4.结构稳定5.分支点均衡
适应函数的每个部分都归约到[0, 1],假设每个节点的坐标(x,y)
趋光性表示为:所有节点中最高节点的高度,达到“高”的标准后适应度为好
双边平衡性表示为:所有x大于0节点的x值和x小于0的节点的x值得绝对值的比值,月接近1则双边平衡性好
采光能力表示为:暴露在光下的表面积,可用最大X减最小X表示
结构稳定:植物从一个分支节点产生的分支数被计算,拥有过多分支的评价低
分支点均衡:有超过一个叶子分支的分支节点的总数被计算,数越高则月能接受阳光和分散种子。
最后的适应度则是给五个部分加权平均
Section 3
一些给定不同权重后产生的结果图片
Section 4
L -system 组成充分的自然形态基因表示,可以方便的在基因型和显型中转换,满足生物学的特征,满足小的改变产生小的性状改变,corsscover能够混合两种性状。以后可以考虑更复杂的L-system比如多个规则的基因型和3D形态
Adventures in level design: generating missions and spaces for action adventure games
Dormans, J. (2010). Adventures in level design: generating missions and spaces for action adventure games. In Proceedings of the 2010 Workshop on Procedural Content Generation in Games (p. 1). ACM.
Abstract
本文讨论了动作冒险游戏的生成,这种游戏着重于关卡设计而不是规则设计。本文讨论的方法把任务和空间分为两种结构,在两步中分别生成。讨论了每一步不同生产语法的优势。
Section 1
新游戏的源码一般不可得,旧游戏的典型PCG方法可以分类为:
brute-force random algorithm that is tailored to the purpose of generating level structures that function for the type of game。
一个方法是假设地图全都充满岩石,我们从入口钻出通道和房间,从之前的地方改变方向想可以钻出多条路径,之后再添加财宝陷阱等
另外一个方法是先把地下城分为大区,在一些区产生房间然后最后由走廊相连。
要产生大地图,还一个方法是cellular automata
这些方法对于需要角色养成的游戏支持不大
对于动作冒险游戏关卡设计很重要,因为这类游戏依赖关卡设计来达成有趣的探险,遵循叙事结构。以上的算法不能遵循这个原则,因为他们都是大范围的生成而不是针对单独的地下城房间或走廊。用generative grammar可以遵循这个原则,本文讲述用不同generative grammar生成mission和space,先mission后space
Section 2: mission and space
任务由有向图表示,指明游戏的逻辑顺序,space抽象成网络节点和边
space 适应mission,mission映射space, 除此之外两者独立。而且两者是多对多的,线性任务可以分配给非线性空间,非线性任务可以分配给线性空间
Section 3: generative grammars
generative grammar起源于语言学用来作为描述语言学短语的模型。它由字母和规则组成,比如S 可以替换为ab。a和b为terminal因为么有对应的替换规则。S通常作为开始符号。它可用来描述游戏,只需symble变为游戏概念,规则定义概念在关卡中是如何相关联的1. Dungeon Obstacle + treasure 2. Obstacle key + Obstacle + lock + Obstacle 3. Obstacle monster + Obstacle 4. Obstacle room。
Section 4: graph grammar to generate missions
graph grammar产生的不是string而是graph,在graph grammar中节点和内联边可以由新节点和边代替,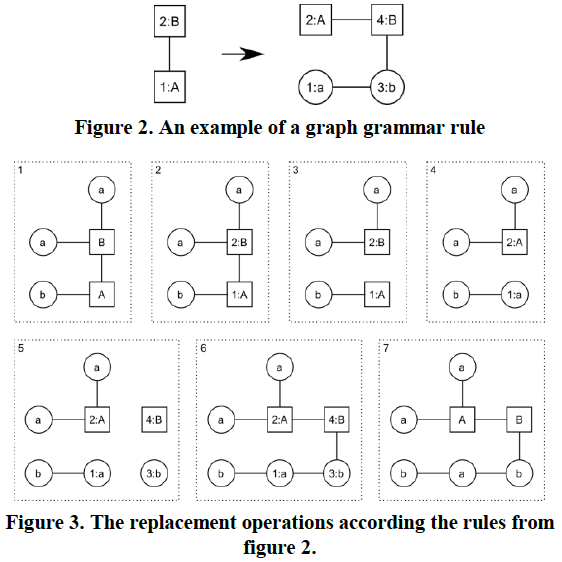
(没看懂)
graph grammar很适合产生任务因为任务可以由非线性图表示,
Section 5: shape grammar to generate space
根据rule替换图形:假设 有墙,open space 和连接 三种图形,只有连接是non-terminal的,从连接开始替换。替换可以是递归的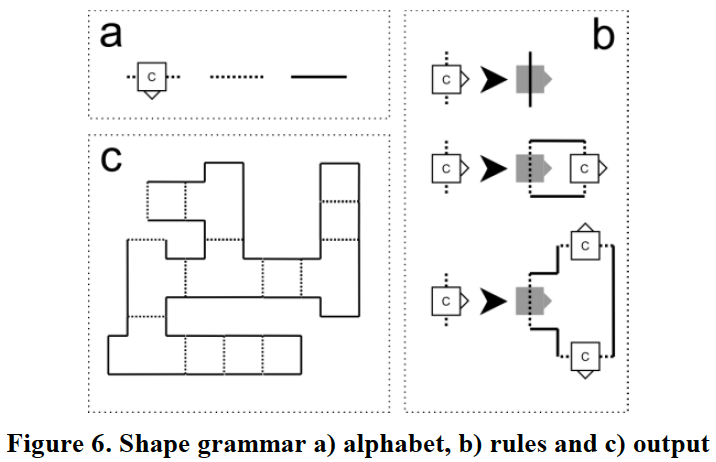
Section 6: 从任务产生shape
为了从任务产生,shape grammar需要改变,mission中的terminal需要作为shape中的building instruction,如此需要每一个shape grammar中的rule和一个mission中的symbol相连:
shape grammar寻找任务的下一个symbol,找到符合symbol的rules,再基于权重随机选一个。然后找到一个最适合的位置放置shape。一些参数可以用来影响rule的选择,从而改变难度,比如选择更多怪兽的obstacle或者更多traps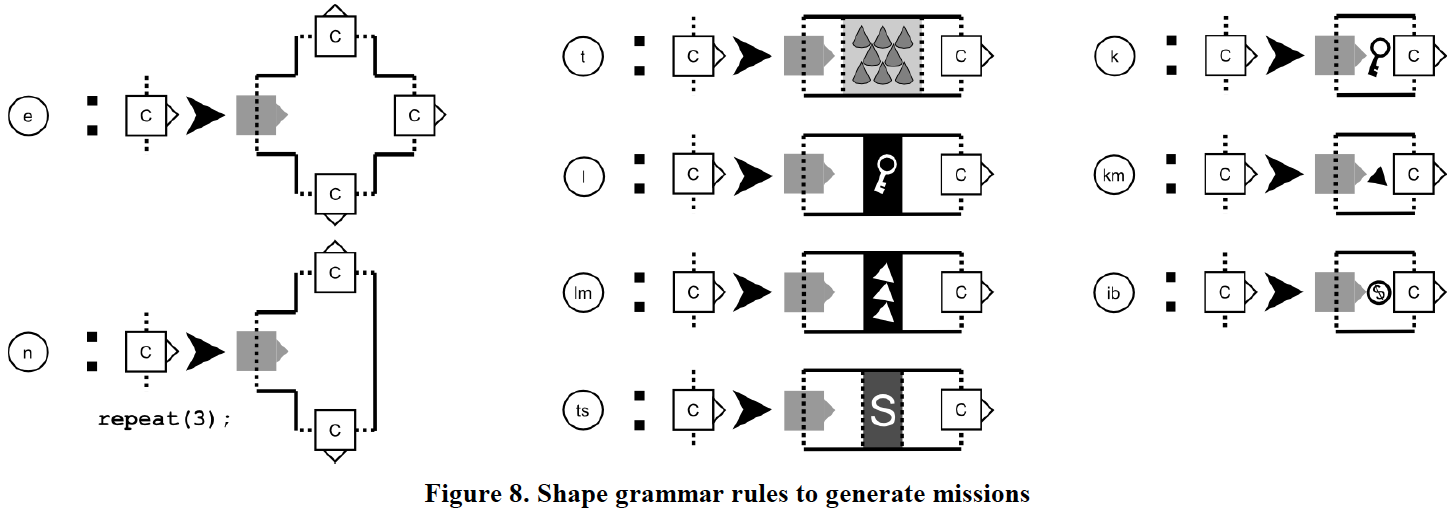
Section 7: involve player performance
以上方法可以在玩游戏过程中产生level,space grow 根据玩家的移动,这样需要rule的动态权重,从而根据玩家的表现生成世界。比如玩家打了很多怪了,则生成很多怪物的权重减少。
Procedural Generation of Dungeons
van der Linden, R., Lopes, R., & Bidarra, R. (2014). Procedural generation of dungeons. Computational Intelligence and AI in Games, IEEE Transactions on, 6(1), 78-89.
Section 1
Lack of PCG in commercial because lack of control, result is unpredictable.
Benefit: rapid generation of content, possible diversity of content, time and money save, can provide auto adapt to players
Definition of dungeon generation.
Control challenges: 地下城游戏的地图和游戏进程相关,尽管是开放的,但是只有到达特定游 戏进度后才有能力探索。(bound between gameplay and game space)关卡生成要结构化而不是出人意料的结果
Close relationship with successful games.
本文 Section 2 介绍地下城产生方法以及方法如何被 controll; Section 3 - 6: 具体描述 (Cellular Automata, Generative Grammars, Genetic Algorithms, Constraint-Based); Section 7: 其他肯可能帮助产生地下城的方法; Section 8: 回顾和讨论
Section 2
Dungeon generation 是产生关卡的拓扑结构,形状和物体
产生方法需要三个元素:
- 关卡的抽象表示
- 构建抽象表示关卡的方法
- 从模型创建真实几个形状的方法
Control 是设计者能够控制关卡产生过程的度,比如你输入的参数能够在多少程度上控制输出的结果。缺少 control 会使产生的结果不确定
Section 3
CELLULAR AUTOMATA,定义细胞的转换规则,随机开始然后一代一代产生新细胞
高效,产生无限地图,感觉自然。
缺少控制,只能2D
控制参数:rock, cell的比例,更新的代数,变为rock的临界值,相邻细胞的个数
不能确定参数对于generation的具体影响,无法产生要求具体的结构
Section 4
GENERATIVE GRAMMARS
先使用graph grammar产生有向图形式的任务,作为玩家行动的序列,抽象成成网络节点和边。然后由shape grammar产生space。这个方法里没有parameter,因为control是由两种grammar体现的。人可以手动改变grammar,添加自己定义的任务比如钥匙和门锁。还有一种gameplay grammar,和前面类似,设计一些用户在游戏中的行为(比如打boss,捡起血包)作为参数,产生不同的grammar,然后产生关卡。Grammar就是control
Section 5
GENETIC ALGORITHMS
generate game world based on story, 使用岛和桥的隐喻,岛是故事发生的地方,桥连接岛。岛和桥形成space tree, 其中包含环境类型信息。使用进化算法 创造space tree, fitness fountain 评估相连的环境类型信息(比如某类一般在另一类之后发生)和玩家风格(确定长度和分支数) 使用tree生成游戏世界,如果没有solution就丢弃重来
好处是game story有效地图就是有意义的
缺点是当故事元素多起来不知道好不好使用遗传控制,而且由于老是丢弃不要的不知道效率如何。
还有一个例子也用遗传,房间是节点,边是房间的连接,fitness function喜欢紧凑相连的房间,以及event room在边缘的房间。 房间很整齐
四种遗传算法表示maze的方法:1gene表示墙,2.gene表示颜色,3.gene表示放置的结构4.gene表示移除的结构
3个fitness: 最大化进出口距离,最大化达到checkpoint的能力,鼓励先分支路过checkpoint再集合
Control最主要由fitness function决定。缺点是结果出现后要调整不知道如何更改parameter
Sentient Sketchbook 可以从草稿地图细节化形成有效地图。一个草稿表示可通过和不可通过的节点,可自动添加路径,房间。由当前地图使用进化算法改变地图,根据一些参数比如安全区分布,财宝的安全性探索难度等。sketch 和fitness有很强的control
CONSTRAINT-BASED
先产生无向3D图,节点表示具体关卡的一部分,由距离和临接这些限制来指导几何图形产生。control由初始的拓扑图形和一些限制形成。然而设计者不容易把游戏内容转化为拓扑和临接。
Section 6
使用混合方法来PCG,可以结合不同方法的好处,比如 ASP 结果集 programming 和进化搜索结合。ASP作为 genotype-to-phenotype mapping of a 进化搜索算法
Section 7
TABEL: OVERVIEW OF SURVEYED METHODS AND THEIR PROPERTIES
1 | father(x,y). |
Week 7: Game Generation
An Experiment in Automatic Game Design
Togelius, J., & Schmidhuber, J. (2008). An experiment in automatic game design. In Computational Intelligence and Games, 2008. CIG’08. IEEE Symposium On (pp. 111-118). IEEE.
Evolutionary Game Design
Browne, C., & Maire, F. (2010). Evolutionary game design. IEEE Transactions on Computational Intelligence and AI in Games, 2(1), 1-16.
Automatic Game Design via Mechanic Generation
Zook, A., & Riedl, M. O. (2014). Automatic game design via mechanic generation. In Proceedings of the 28th AAAI Conference on Artificial Intelligence.
Towards Generating Arcade Game Rules with VGDL
Nielsen, T. S., Barros, G. A., Togelius, J., & Nelson, M. J. (2015). Towards generating arcade game rules with VGDL. In IEEE Conference on Computational Intelligence and Games (CIG) (pp. 185-192). IEEE.
Week 8: AI-assisted gamed design tools
Tanagra: Reactive Planning and Constraint Solving for Mixed-initiative Level Design
Smith, G., Whitehead, J., & Mateas, M. (2011). Tanagra: Reactive planning and constraint solving for mixed-initiative level design. IEEE Transactions on Computational Intelligence and AI in Games, 3(3), 201-215.
Sentient Sketchbook: Computer-aided Game Level Authoring
Liapis, A., Yannakakis, G. N., & Togelius, J. (2013). Sentient Sketchbook: Computer-aided game level authoring. In FDG (pp. 213-220).
Ropossum: An Authoring Tool for Designing, Optimizing and Solving Cut the Rope Levels
Shaker, N., Shaker, M., & Togelius, J. (2013, November). Ropossum: An Authoring Tool for Designing, Optimizing and Solving Cut the Rope Levels. InAIIDE.
A Mixed-initiative Tool for Designing Level Progressions in Games
Butler, E., Smith, A. M., Liu, Y. E., & Popovic, Z. (2013, October). A mixed-initiative tool for designing level progressions in games. In Proceedings of the 26th annual ACM symposium on User interface software and technology (pp. 377-386). ACM.